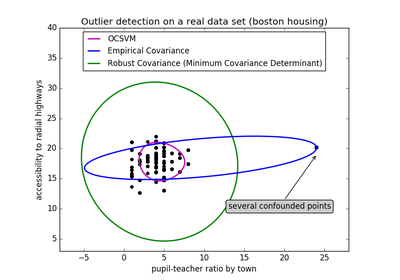
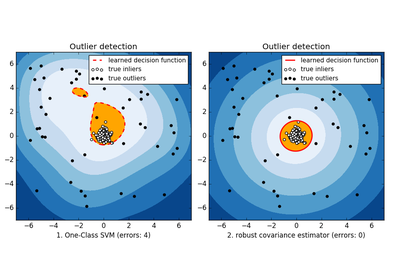
sklearn.covariance.EllipticEnvelope¶
-
class
sklearn.covariance.EllipticEnvelope(store_precision=True, assume_centered=False, support_fraction=None, contamination=0.1, random_state=None)[源代码]¶ An object for detecting outliers in a Gaussian distributed dataset.
Read more in the User Guide.
Parameters: store_precision : bool
Specify if the estimated precision is stored.
assume_centered : Boolean
If True, the support of robust location and covariance estimates is computed, and a covariance estimate is recomputed from it, without centering the data. Useful to work with data whose mean is significantly equal to zero but is not exactly zero. If False, the robust location and covariance are directly computed with the FastMCD algorithm without additional treatment.
support_fraction : float, 0 < support_fraction < 1
The proportion of points to be included in the support of the raw MCD estimate. Default is
None, which implies that the minimum value of support_fraction will be used within the algorithm: [n_sample + n_features + 1] / 2.contamination : float, 0. < contamination < 0.5
The amount of contamination of the data set, i.e. the proportion of outliers in the data set.
Attributes: `contamination` : float, 0. < contamination < 0.5
The amount of contamination of the data set, i.e. the proportion of outliers in the data set.
location_ : array-like, shape (n_features,)
Estimated robust location
covariance_ : array-like, shape (n_features, n_features)
Estimated robust covariance matrix
precision_ : array-like, shape (n_features, n_features)
Estimated pseudo inverse matrix. (stored only if store_precision is True)
support_ : array-like, shape (n_samples,)
A mask of the observations that have been used to compute the robust estimates of location and shape.
Notes
Outlier detection from covariance estimation may break or not perform well in high-dimensional settings. In particular, one will always take care to work with
n_samples > n_features ** 2.References
[1] Rousseeuw, P.J., Van Driessen, K. “A fast algorithm for the minimum covariance determinant estimator” Technometrics 41(3), 212 (1999) Methods
correct_covariance(data)Apply a correction to raw Minimum Covariance Determinant estimates. decision_function(X[, raw_values])Compute the decision function of the given observations. error_norm(comp_cov[, norm, scaling, squared])Computes the Mean Squared Error between two covariance estimators. fit(X[, y])get_params([deep])Get parameters for this estimator. get_precision()Getter for the precision matrix. mahalanobis(observations)Computes the squared Mahalanobis distances of given observations. predict(X)Outlyingness of observations in X according to the fitted model. reweight_covariance(data)Re-weight raw Minimum Covariance Determinant estimates. score(X, y[, sample_weight])Returns the mean accuracy on the given test data and labels. set_params(**params)Set the parameters of this estimator. -
__init__(store_precision=True, assume_centered=False, support_fraction=None, contamination=0.1, random_state=None)[源代码]¶
-
correct_covariance(data)[源代码]¶ Apply a correction to raw Minimum Covariance Determinant estimates.
Correction using the empirical correction factor suggested by Rousseeuw and Van Driessen in [Rouseeuw1984].
Parameters: data : array-like, shape (n_samples, n_features)
The data matrix, with p features and n samples. The data set must be the one which was used to compute the raw estimates.
Returns: covariance_corrected : array-like, shape (n_features, n_features)
Corrected robust covariance estimate.
-
decision_function(X, raw_values=False)[源代码]¶ Compute the decision function of the given observations.
Parameters: X : array-like, shape (n_samples, n_features)
raw_values : bool
Whether or not to consider raw Mahalanobis distances as the decision function. Must be False (default) for compatibility with the others outlier detection tools.
Returns: decision : array-like, shape (n_samples, )
The values of the decision function for each observations. It is equal to the Mahalanobis distances if raw_values is True. By default (
raw_values=True), it is equal to the cubic root of the shifted Mahalanobis distances. In that case, the threshold for being an outlier is 0, which ensures a compatibility with other outlier detection tools such as the One-Class SVM.
-
error_norm(comp_cov, norm='frobenius', scaling=True, squared=True)[源代码]¶ Computes the Mean Squared Error between two covariance estimators. (In the sense of the Frobenius norm).
Parameters: comp_cov : array-like, shape = [n_features, n_features]
The covariance to compare with.
norm : str
The type of norm used to compute the error. Available error types: - ‘frobenius’ (default): sqrt(tr(A^t.A)) - ‘spectral’: sqrt(max(eigenvalues(A^t.A)) where A is the error
(comp_cov - self.covariance_).scaling : bool
If True (default), the squared error norm is divided by n_features. If False, the squared error norm is not rescaled.
squared : bool
Whether to compute the squared error norm or the error norm. If True (default), the squared error norm is returned. If False, the error norm is returned.
Returns: The Mean Squared Error (in the sense of the Frobenius norm) between :
`self` and `comp_cov` covariance estimators. :
-
get_params(deep=True)[源代码]¶ Get parameters for this estimator.
Parameters: deep: boolean, optional :
If True, will return the parameters for this estimator and contained subobjects that are estimators.
Returns: params : mapping of string to any
Parameter names mapped to their values.
-
get_precision()[源代码]¶ Getter for the precision matrix.
Returns: precision_ : array-like,
The precision matrix associated to the current covariance object.
-
mahalanobis(observations)[源代码]¶ Computes the squared Mahalanobis distances of given observations.
Parameters: observations : array-like, shape = [n_observations, n_features]
The observations, the Mahalanobis distances of the which we compute. Observations are assumed to be drawn from the same distribution than the data used in fit.
Returns: mahalanobis_distance : array, shape = [n_observations,]
Squared Mahalanobis distances of the observations.
-
predict(X)[源代码]¶ Outlyingness of observations in X according to the fitted model.
Parameters: X : array-like, shape = (n_samples, n_features)
Returns: is_outliers : array, shape = (n_samples, ), dtype = bool
For each observations, tells whether or not it should be considered as an outlier according to the fitted model.
threshold : float,
The values of the less outlying point’s decision function.
-
reweight_covariance(data)[源代码]¶ Re-weight raw Minimum Covariance Determinant estimates.
Re-weight observations using Rousseeuw’s method (equivalent to deleting outlying observations from the data set before computing location and covariance estimates). [Rouseeuw1984]
Parameters: data : array-like, shape (n_samples, n_features)
The data matrix, with p features and n samples. The data set must be the one which was used to compute the raw estimates.
Returns: location_reweighted : array-like, shape (n_features, )
Re-weighted robust location estimate.
covariance_reweighted : array-like, shape (n_features, n_features)
Re-weighted robust covariance estimate.
support_reweighted : array-like, type boolean, shape (n_samples,)
A mask of the observations that have been used to compute the re-weighted robust location and covariance estimates.
-
score(X, y, sample_weight=None)[源代码]¶ Returns the mean accuracy on the given test data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
Parameters: X : array-like, shape = (n_samples, n_features)
Test samples.
y : array-like, shape = (n_samples) or (n_samples, n_outputs)
True labels for X.
sample_weight : array-like, shape = [n_samples], optional
Sample weights.
Returns: score : float
Mean accuracy of self.predict(X) wrt. y.
-