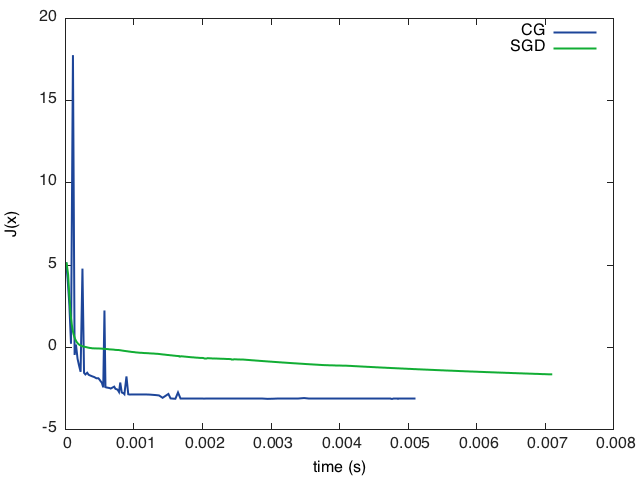
x = torch.rand(N) lr = 0.01 for i=1,20000do x = x - dJ(x)*lr -- 输出每次迭代的目标函数值 print(string.format('at iter %d J(x) = %f', i, J(x))) end
样例输出:
1 2 3 4 5 6 7
... at iter 19995 J(x) = -3.135664 at iter 19996 J(x) = -3.135664 at iter 19997 J(x) = -3.135665 at iter 19998 J(x) = -3.135665 at iter 19999 J(x) = -3.135665 at iter 20000 J(x) = -3.135666
使用optim包
默认已经安装了optim包,如果没安装,可以使用luarocks install optim安装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
do local neval = 0 functionJdJ(x) local Jx = J(x) neval = neval + 1 print(string.format('after %d evaluations J(x) = %f', neval, Jx)) return Jx, dJ(x) end end
require'optim'
state = { verbose = true, maxIter = 100 }
x = torch.rand(N) optim.cg(JdJ, x, state)
样例输出:
1 2 3 4 5 6 7
... after 120 evaluation J(x) = -3.136835 after 121 evaluation J(x) = -3.136836 after 122 evaluation J(x) = -3.136837 after 123 evaluation J(x) = -3.136838 after 124 evaluation J(x) = -3.136840 after 125 evaluation J(x) = -3.136838