Monomer
(ICDM 2016) Learning Compatibility Across Categories for Heterogeneous Item Recommendation
Paper: https://cseweb.ucsd.edu/~jmcauley/pdfs/icdm16b.pdf
Introduction
Identifying and understanding relationships between items is a key component of any modern recommender system.
Knowing which items are 'similar', or which otherwise may be substitutable or complementary.
However, identifying such a similarity measure may be insufficient when there is substantial heterogeneity between the items being considered.
Such methods work to some extent even in the presence of heterogeneity, since they learn to 'ignore' dimensions where similarity should not be preserved. But
we argue that ignoring such dimensions discards valuable information that ought to be used for prediction and recommendation.
we relax the metricity assumption present in recent work, by proposing more flexible notions of 'relatedness' while maintaining the same levels of speed and scalability.
we hope to overcome the following limitations of previous work:
ultimately project categories as clusters into a metric space. cross-category recommendations can only be made by exploiting an explicit category tree.
Other assumptions made by metric learning approaches are also too strict for recommendation.
neglecting any 'local' notions that could be equally important.
We propose a novel method, Mixtures of Non-Metric Embeddings for Recommendation, or Monomer for short.
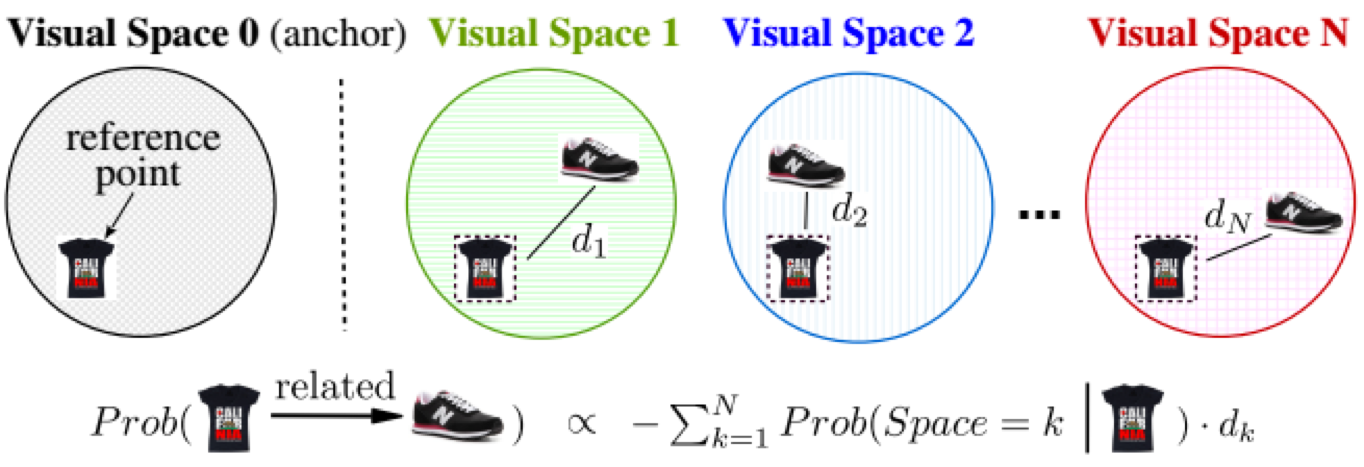
Figure 1: Illustration of the high-level ideas of Monomer. The query item (a t-shirt) is embedded into visual space 0 (the anchor space) whose position we superimpose into the other spaces. The potential match (a shoe) is embedded to N visual spaces and within each of them Euclidean distance between the pair is computed. Finally, the mixtures-of-experts framework is adopted to model the relative importance of the different components w.r.t. the given query.
we embed the first item x (the query) into one space (the 'anchor space'), and embed its potential match y into a series of N additional spaces.
Contributions:
Monomer, for heterogeneous item-to-item recommendation, learn non-metric relationships, thereby overcoming multiple limitations present in existing work.
effective at learning notions of 'relatedness' from heterogeneous dyads of co-purchases. more accurately than recent approaches based on metric/similarity learning.
effectively learn multiple, semantically complex notions of 'relatedness'. useful to generate rich, heterogeneous, and diverse sets of recommendations.



