Look Into Person
- Introduction
- Look into Person Benchmark
- Empirical study of state-of-the-arts
- Self-supervised Structure-sensitive Learning
- Experiments
- Conclusions
(CVPR 2017) Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing
Paper: http://www.linliang.net/files/CVPR17_LIP.pdf
Project: http://hcp.sysu.edu.cn/lip/index.php
Code: https://github.com/Engineering-Course/LIP_SSL
提出一个大规模的人体解析数据集,包含50,000张图片,19个带语义的人体部位标签,16个人体姿势关键点。
提出一种自监督结构敏感的学习方法来解决人的解析问题,它将人的姿势结构引入到解析结果中,而无需额外的监督。
定义9个关节点(头,上身,下身,左臂,右臂,左腿,右腿,左鞋,右鞋)构成一个姿势,使用不同部位区域的中心点作为关节点。标签为帽子、头发、太阳眼镜、脸的构成头部区域,上衣、大衣、围巾构成上身区域,裤子、裙子构成下衣区域,其它同理。
训练时同时训练分割及关节点,关节点loss为L2 loss,最终loss为关节点loss与分割loss的乘积。
We present a new large-scale dataset focusing on semantic understanding of person.
50,000 images with elaborated pixel-wise annotations with 19 semantic human part labels and 2D human poses with 16 key points.
The annotated 50,000 images are cropped person instances from COCO dataset with size larger than 50 * 50.
The images collected from the real-world scenarios contain human appearing with challenging poses and views, heavily occlusions, various appearances and low-resolutions.
we solve human parsing by exploring a novel self-supervised structure-sensitive learning approach, which imposes human pose structures into parsing results without resorting to extra supervision.
Introduction
the performance of those CNN-based approaches heavily rely on the availability of annotated images for training.
The largest public human parsing dataset so far only contains 17,000 fashion images while others only include thousands of images.
we propose a new benchmark “Look into Person (LIP)” and a public server for automatically reporting evaluation results.
Our benchmark significantly advances the state-of-the-arts in terms of appearance variability and complexity, which includes 50,462 human images with pixel-wise annotations of 19 semantic parts.
Without imposing human body structure priors, these general approaches based on bottom-up appearance information sometimes tend to produce unreasonable results (e.g., right arm connected with left shoulder).
difficult to directly utilize joint-based pose estimation models in pixel-wise prediction to incorporate the complex structure constraints.
we propose a novel structure-sensitive learning approach for human parsing.
we introduce a structure-sensitive loss to evaluate the quality of predicted parsing results from a joint structure perspective.
we generate approximated human joints directly from the parsing annotations and use them as the supervision signal for the structure-sensitive loss, which is hence called a “self-supervised” strategy, noted as Self-supervised Structure-sensitive Learning (SSL).
contributions:
We propose a new large-scale benchmark and an evaluation server to advance the human parsing research, in which 50,462 images with pixel-wise annotations on 19 semantic part labels are provided.
we present the detailed analyses about the existing human parsing approaches to gain some insights into the success and failures of these approaches.
We propose a novel self-supervised structure-sensitive learning framework for human parsing, which is capable of explicitly enforcing the consistency between the parsing results and the human joint structures.
Related Work
Human parsing datasets
| Dataset | #Training | #Validation | #Test | Categories |
|---|---|---|---|---|
| Fashionista | 456 | - | 229 | 56 |
| PASCAL-Person-Part | 1,716 | - | 1,817 | 7 |
| ATR | 16,000 | 700 | 1,000 | 18 |
| LIP | 30,462 | 10,000 | 10,000 | 20 |
Human parsing approaches
Look into Person Benchmark
Image Annotation
The images in the LIP dataset are cropped person instances from Microsoft COCO training and validation sets. We defined 19 human parts or clothes labels for annotation, which are hat, hair, sunglasses, upper-clothes, dress, coat, socks, pants, gloves, scarf, skirt, jumpsuits, face, right arm, left arm, right leg, left leg, right shoe, left shoe, and in addition to a background label.
Dataset splits
In total, there are 50,462 images in the LIP dataset including 19,081 full-body images, 13,672 upper-body images, 403 lower-body images, 3,386 head-missed images, 2,778 back-view images and 21,028 images with occlusions. Following random selection, we arrive at a unique split consisting of 30,462 training and 10,000 validation images with publicly available annotations, as well as 10,000 test images with annotations withheld for benchmarking purpose.
Dataset statistics
The images in the LIP dataset contain diverse human appearances, viewpoints and occlusions.
Empirical study of state-of-the-arts
we consider fully convolutional networks (FCN-8s), a deep convolutional encoderdecoder architecture (SegNet), deep convolutional nets with atrous convolution and multi-scale (DeepLabV2) and an attention mechanism (Attention).
we train each method on our LIP training set for 30 epochs and evaluate on the validation set and the test set.
For DeepLabV2, we use the VGG-16 model without dense CRFs.
Overall performance evaluation
We begin our analysis by reporting the overall human parsing performance of each approach and summarize the results in Table. 2 and Table. 3.
| Method | Overall accuracy | Mean accuracy | Mean IoU |
|---|---|---|---|
| SegNet | 69.04 | 24 | 18.17 |
| FCN-8s | 76.06 | 36.75 | 28.29 |
| DeepLabV2 | 82.66 | 51.64 | 41.64 |
| Attention | 83.43 | 54.39 | 42.92 |
| DeepLabV2 + SSL | 83.16 | 52.55 | 42.44 |
| Attention + SSL | 84.36 | 54.94 | 44.73 |
Table 2: Comparison of human parsing performance with four state-of-the-art methods on the LIP validation set.
| Method | Overall accuracy | Mean accuracy | Mean IoU |
|---|---|---|---|
| SegNet | 69.10 | 24.26 | 18.37 |
| FCN-8s | 76.28 | 37.18 | 28.69 |
| DeepLabV2 | 82.89 | 51.53 | 41.56 |
| Attention | 83.56 | 54.28 | 42.97 |
| DeepLabV2 + SSL | 83.37 | 52.53 | 42.46 |
| Attention + SSL | 84.53 | 54.81 | 44.59 |
Table 3: Comparison of human parsing performance with four state-of-the-art methods on the LIP test set.
Performance evaluation under different challenges
We further analyse the performance of each approach with respect to the following five challenging factors: occlusion, full-body, upper-body, head-missed and back-view (see Fig. 5).
Per-class performance evaluation
we further report the performance of per-class IoU on the LIP validation set, shown in Table. 4.
Visualization comparison
The qualitative comparisons of four approaches on our LIP validation set are visualized in Fig. 8.
Self-supervised Structure-sensitive Learning
Overview
a major limitation of the existing human parsing approaches is the lack of consideration of human body configuration
The pixel-wise labeling can address more detailed information while joint-wise structure provides more high-level structure.
The predicted joints do not have high enough quality to guide human parsing compared with the joints extracted from parsing annotations. Moreover, the joints in pose estimation are not aligned with parsing annotations.
we investigate how to leverage informative high-level structure cues to guide pixel-wise prediction.
We propose a novel self-supervised structure-sensitive learning for human parsing, which introduces a self-supervised structure-sensitive loss to evaluate the quality of predicted parsing results from a joint structure perspective
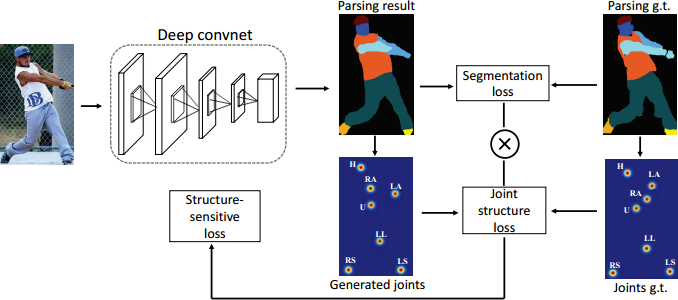
Figure 6: Illustration of our Self-supervised Structure-sensitive Learning for human parsing. An input image goes through parsing networks including several convolutional layers to generate the parsing results. The generated joints and joints ground truth represented as heatmaps are obtained by computing the center points of corresponding regions in parsing maps, including head (H), upper body (U), lower body (L), right arm (RA), left arm (LA), right leg (RL), left leg (LL), right shoe (RS), left shoe (LS). The structure-sensitive loss is generated by weighting segmentation loss with joint structure loss. For clear observation, here we combine nine heatmaps into one map.
Specifically, in addition to using the traditional pixel-wise annotations as the supervision, we generate the approximated human joints directly from the parsing annotations which can also guide human parsing training.
Self-supervised Structure-sensitive Loss
We define 9 joints to construct a pose structure, which are the centers of regions of head, upper body, lower body, left arm, right arm, left leg, right leg, left shoe and right shoe.
The region of head are generated by merging parsing labels of hat, hair, sunglasses and face. Similarly, upper-clothes, coat and scarf are merged to be upper body, pants and skirt for lower body.
for each parsing result and corresponding ground truth, we compute the center points of regions to obtain joints represented as heatmaps for training more smoothly.
use Euclidean metric to evaluate the quality of the generated joint structures
the pixel-wise segmentation loss is weighted by the joint structure loss, which becomes our structure-sensitive loss.
Experiments
Experimental Settings
Dataset
PASCAL-Person-part dataset with 1,716 images for training and 1,817 for testing
large-scale LIP dataset
Network architecture
Attention [5], as the basic architecture
Training
We use the pre-trained models and networks settings provided by DeepLabV2 [4].
The scale of the input images is fixed as 321 × 321 for training networks based on Attention [5].
we train the basic network on our LIP dataset for 30 epochs, which takes about two days.
we perform “self-supervised” strategy to fine-tune our model with structure-sensitive loss. We fine-tune the networks for roughly 20 epochs and it takes about one and a half days.
Reproducibility
Results and Comparisons
PASCAL-Person-Part dataset
| Method | head | torso | u-arms | l-arms | u-legs | l-legs | Bkg | Avg |
|---|---|---|---|---|---|---|---|---|
| DeepLab-LargeFOV | 78.09 | 54.02 | 37.29 | 36.85 | 33.73 | 29.61 | 92.85 | 51.78 |
| HAZN | 80.79 | 59.11 | 43.05 | 42.76 | 38.99 | 34.46 | 93.59 | 56.11 |
| Attention | 81.47 | 59.06 | 44.15 | 42.50 | 38.28 | 35.62 | 93.65 | 56.39 |
| LG-LSTM | 82.72 | 60.99 | 45.40 | 47.76 | 42.33 | 37.96 | 88.63 | 57.97 |
| Attention + SSL | 83.26 | 62.40 | 47.80 | 45.58 | 42.32 | 39.48 | 94.68 | 59.36 |
Table 5: Comparison of person part segmentation performance with four state-of-the-art methods on the PASCALPerson-Part dataset.
LIP dataset
We report the results and the comparisons with four state-of-the-art methods on LIP validation set and test set in Table. 2 and Table. 3.
Qualitative Comparison
Further experiments and analyses
Conclusions
In this work, we presented “Look into Person (LIP)”, a large-scale human parsing dataset and a carefully designed benchmark to spark progress in human parsing.
we design a novel learning strategy, namely self-supervised structure-sensitive learning, to explicitly enforce the produced parsing results semantically consistent with the human joint structures.



