神经网络模型压缩与加速
介绍神经网络(主要是CNN)模型压缩与加速的常见方法
目标:模型运行速度尽可能快,大小尽可能小,准确率尽可能保持不变
模型压缩
改变网络结构
使用特定结构
如 ShuffleNet, MobileNet, Xception, SqueezeNet
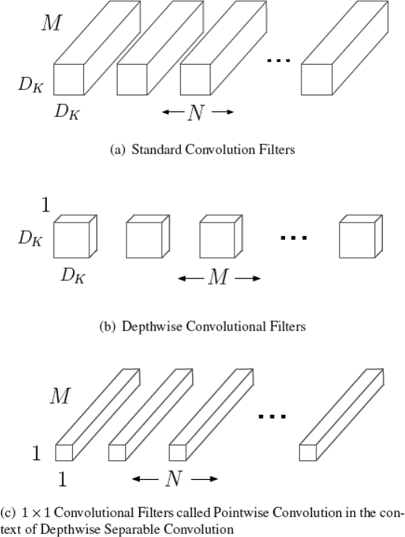
MobileNet
把普通卷积操作分成两部分
Depthwise Convolution
计算量 \(D_K \cdot D_K \cdot M \cdot D_F \cdot D_F\)
Pointwise Convolution
计算量 \(M \cdot N \cdot D_F \cdot D_F\)
上面两步合称Depthwise Separable Convolution
与原卷积计算量之比 \(\frac{D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot N \cdot D_F \cdot D_F}{D_K \cdot D_K \cdot M \cdot N \cdot D_F \cdot D_F} = \frac{1}{N} + \frac{1}{D_K^2}\)
参考:
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices https://arxiv.org/abs/1707.01083
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications https://arxiv.org/abs/1704.04861 https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md
Xception: Deep Learning with Depthwise Separable Convolutions https://arxiv.org/abs/1610.02357
(ICLR 2017) Squeezenet: Alexnet-level Accuracy with 50x Fewer Parameters and <0.5MB Model Size https://arxiv.org/abs/1602.07360 https://github.com/DeepScale/SqueezeNet
剪枝
裁剪连接、滤波器
权值稀疏化
参考:
(ICLR 2017) Pruning Filters for Efficient Convnets https://arxiv.org/abs/1608.08710
(ICLR 2016) Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding https://arxiv.org/abs/1510.00149 https://github.com/songhan/Deep-Compression-AlexNet
(NIPS 2015) Learning both Weights and Connections for Efficient Neural Networks https://arxiv.org/abs/1506.02626
蒸馏
用一个性能好的大网络来教小网络学习,使小网络具备跟大网络一样的性能,但参数规模小
训练小模型 (distilled model) 的目标函数由两部分组成:
- 与大模型的softmax输出的交叉熵,称为软目标
- 与groundtruth的交叉熵
训练的损失为上述两项损失的加权和
参考:
(ICLR 2017) Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer https://arxiv.org/abs/1612.03928
(NIPSW 2014) Distilling the Knowledge in a Neural Network https://arxiv.org/abs/1503.02531
只改变权值
量化
把网络权值从高精度转化成低精度(32位浮点数 float32 转化成 8位定点数 int8 或二值化为 1 bit),但模型准确率等指标与原来相近,模型大小变小,运行速度加快。
参考:
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients https://arxiv.org/abs/1606.06160 https://github.com/ppwwyyxx/tensorpack/tree/master/examples/DoReFa-Net
(ECCV 2016) XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks https://arxiv.org/abs/1603.05279 https://github.com/allenai/XNOR-Net
Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to +1 or −1 https://arxiv.org/abs/1602.02830 https://github.com/MatthieuCourbariaux/BinaryNet
BinaryConnect: Training Deep Neural Networks with binary weights during propagations https://arxiv.org/abs/1511.00363 https://github.com/MatthieuCourbariaux/BinaryConnect
(CVPR 2016) Quantized Convolutional Neural Networks for Mobile Devices https://github.com/jiaxiang-wu/quantized-cnn
(ICLR 2016) Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding https://arxiv.org/abs/1510.00149 https://github.com/songhan/Deep-Compression-AlexNet
矩阵分解
低秩分解(SVD分解、Tucker分解、Block Term分解)
原理:权值向量主要分布在一些低秩子空间,用少数基来重构权值矩阵
参考:
(ICCV 2017) Coordinating Filters for Faster Deep Neural Networks https://arxiv.org/abs/1703.09746 https://github.com/wenwei202/caffe
(TPAMI 2015) Accelerating Very Deep Convolutional Networks for Classification and Detection https://arxiv.org/abs/1505.06798
(NIPS 2014) Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation https://papers.nips.cc/paper/5544-exploiting-linear-structure-within-convolutional-networks-for-efficient-evaluation
平台加速
软件加速
卷积计算加速
im2col + GEMM:将问题转化为矩阵乘法后使用矩阵运算库
参考:
- (ICML 2017) MEC: Memory-efficient Convolution for Deep Neural Network https://arxiv.org/abs/1706.06873
FFT变换:时域卷积等于频域相乘,将问题转化为简单的乘法问题
参考:
(BMVC 2015) Very Efficient Training of Convolutional Neural Networks using Fast Fourier Transform and Overlap-and-Add https://arxiv.org/abs/1601.06815
(ICLR 2015) Fast Convolutional Nets With fbfft: A GPU Performance Evaluation https://arxiv.org/abs/1412.7580
Fast Training of Convolutional Networks through FFTs https://arxiv.org/abs/1312.5851
Winograd
参考:
(CODES 2016) Zero and data reuse-aware fast convolution for deep neural networks on gpu
(CVPR 2016) Fast Algorithms for Convolutional Neural Networks https://arxiv.org/abs/1509.09308
不同框架速度不同
- TensorFlow Mobile, TensorFlow Lite https://www.tensorflow.org/mobile/
- Caffe2 https://caffe2.ai/
- 腾讯ncnn(不依赖 BLAS/NNPACK 等计算框架,NEON优化,多核并行) https://github.com/Tencent/ncnn/
- 百度mdl(无任何第三方依赖,汇编优化,NEON优化) https://github.com/baidu/mobile-deep-learning
硬件加速
多GPU并行
多核并行
使用硬件提供最优的指令
如支持arm64则编译64位的库而非32位的库
如使用支持相应 SIMD (Single Instruction, Multiple Data) 的库
参考:
- (ISCA 2016) EIE: Efficient Inference Engine on Compressed Deep Neural Network https://arxiv.org/abs/1602.01528



