PixelDTGAN
- Introduction
- Related Work
- Review of Generative Adversarial Nets
- Pixel-Level Domain Transfer
- Evaluation
- Conclusion
(ECCV 2016) Pixel-Level Domain Transfer
Paper: https://dgyoo.github.io/papers/eccv16.pdf
Supplement: https://dgyoo.github.io/papers/eccv16_supp.pdf
Code: https://github.com/fxia22/PixelDTGAN
Introduction
Our focus of this paper lies on the problem; to enable a machine to transfer a visual input into different forms and to visualize the various forms by generating a pixel-level image.
image-conditioned image generation
all these adaptations take place in the feature space, i.e. the model parameters are adapted. However, our method directly produces target images.
we present a pixel-level domain converter composed of an encoder for semantic embedding of a source and a decoder to produce a target image.
To train our converter, we first place a separate network named domain discriminator on top of the converter. The domain discriminator takes a pair of a source image and a target image, and is trained to make a binary decision whether the input pair is associated or not. Secondly, we also employ the discriminator of [6], which is supervised by the labels of "real" or "fake", to produce realistic images.
source domain: a natural human image
target domain: a product image of the person's top
made a large dataset named LookBook, which contains in total of 84k images, where 75k human images are associated with 10k top product images
Contributions:
- semantically transferring a source domain to a target domain in pixel-level.
- a novel discriminator that enables us to train the semantic relation between the domains.
- a large clothing dataset containing two domains
Related Work
Review of Generative Adversarial Nets
Pixel-Level Domain Transfer
Converter Network
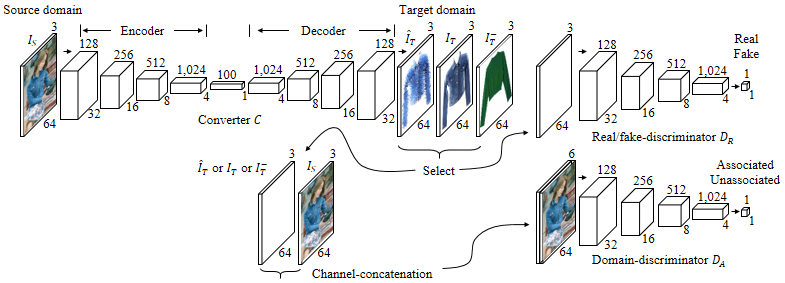
The encoder part is composed of five convolutional layers to abstract the source into a semantic 64-dimensional code.
The decoder constructs a relevant target through the five decoding layers.
Discriminator Networks
Given the converter, a simple choice of a loss function to train it is the mean-square error (MSE) such as \(|| \hat{I}_T − I_T ||^2_2\).
However, MSE is not suitable for pixel-level supervision for natural images, and minimizing MSE always forces the converter to fit into one of the target images.
we place a discriminator network which plays a role as a loss function.
The domain discriminator takes a pair of source and target as input, and produces a scalar probability of whether the input pair is associated or not.
In summary, we employ both of the real/fake discriminator and the domain
discriminator for adversarial training.
The real/fake discriminator penalizes an unrealistic target while the domain discriminator penalizes a target being irrelevant to a source.
Adversarial Training
At first, we train the discriminators.
After that, we freeze the updated discriminator parameters and optimize the converter parameters to increase the losses of both discriminators.
Evaluation
LookBook Dataset
We make a dataset named LookBook that covers two fashion domains. Images of one domain contain fashion models, and those of the other domain contain top products with a clean background.
LookBook contains 84,748 images where 9,732 top product images are associated with 75,016 fashion model images.
Experiment Details
Before training, we rescale all images in LookBook to have 64 pixels at a longer side while keeping the aspect ratio, and fill the margins of both ends with 255s.
randomly select 5% images to define a validation set, and also 5% images for a test set.



