Attention to Scale
(CVPR 2016) Attention to Scale: Scale-aware Semantic Image Segmentation
Paper: https://arxiv.org/abs/1511.03339
Project Page: http://liangchiehchen.com/projects/DeepLab.html
Code: https://bitbucket.org/aquariusjay/deeplab-public-ver2
In this work, we propose an attention mechanism that learns to softly weight the multi-scale features at each pixel location.
we jointly train with multi-scale input images and the attention model.
The proposed attention model not only outperforms average- and max-pooling, but allows us to diagnostically visualize the importance of features at different positions and scales.
Introduction
Successful image segmentation techniques could facilitate a large group of applications such as image editing [17], augmented reality [3] and self-driving vehicles [22].
2 types of network structures that exploit multi-scale features:
skip-net, combines features from the intermediate layers of FCNs.
first trains the deep network backbone and then fixes or slightly fine-tunes during multi-scale feature extraction.
Problem: the training process is not ideal, the training time is usually longshare-net, resizes the input image to several scales and passes each through a shared deep network.
then computes the final prediction based on the fusion of the resulting multi-scale features.
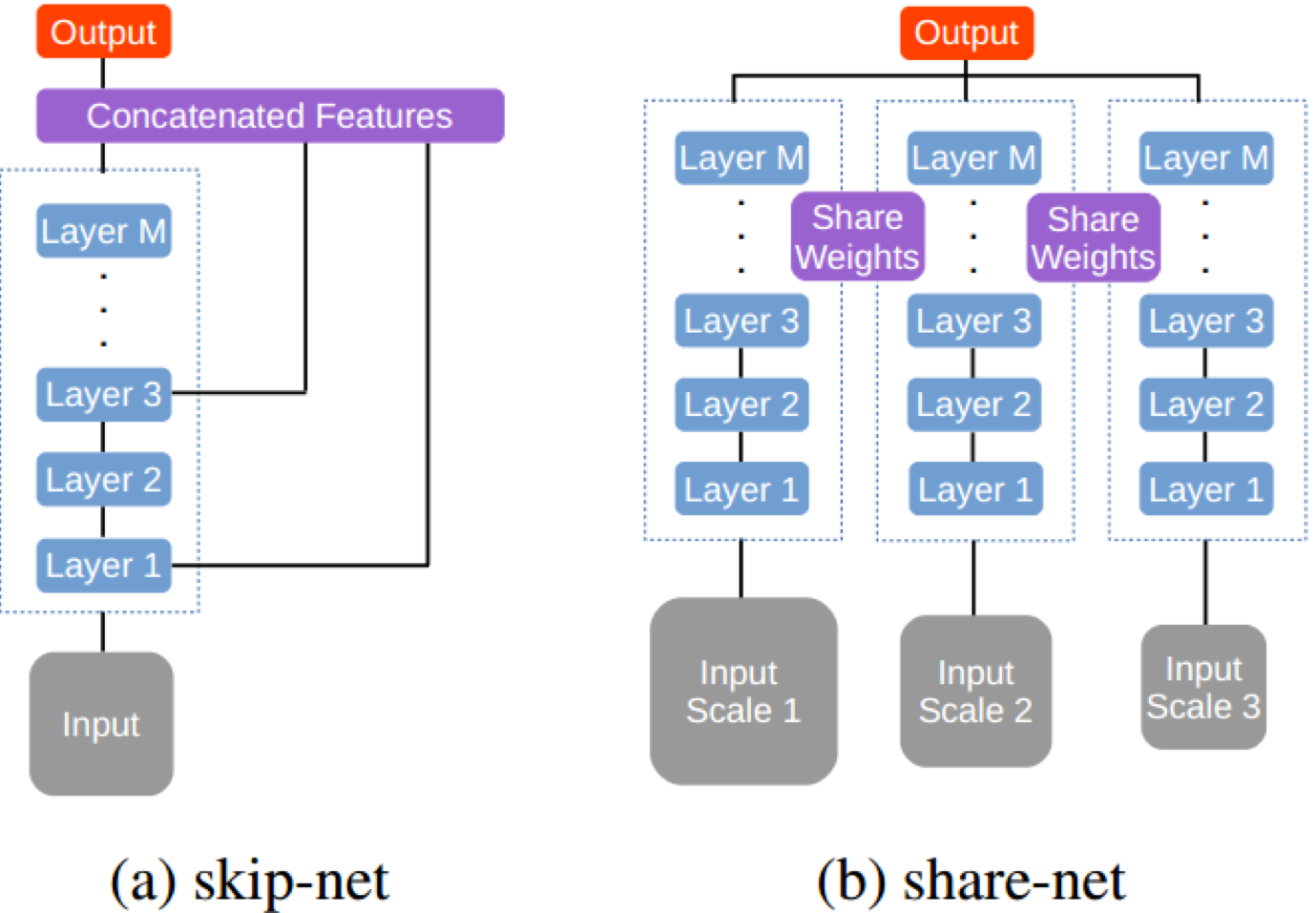
Figure 2. Different network structures for extracting multi-scale features: (a) Skip-net: features from intermediate layers are fused to produce the final output. (b) Share-net: multi-scale inputs are applied to a shared network for prediction. In this work, we demonstrate the effectiveness of the share-net when combined with attention mechanisms over scales.
Rather than compressing an entire image or sequence into a static representation, attention allows the model to focus on the most relevant features as needed.
Unlike previous work that employs attention models in the 2D spatial and/or temporal dimension [48, 56], we explore its effect in the scale dimension.
The proposed attention model learns to weight the multi-scale features according to the object scales presented in the image (e.g., the model learns to put large weights on features at coarse scale for large objects).
For each scale, the attention model outputs a weight map which weights features pixel by pixel, and the weighted sum of FCN-produced score maps across all scales.
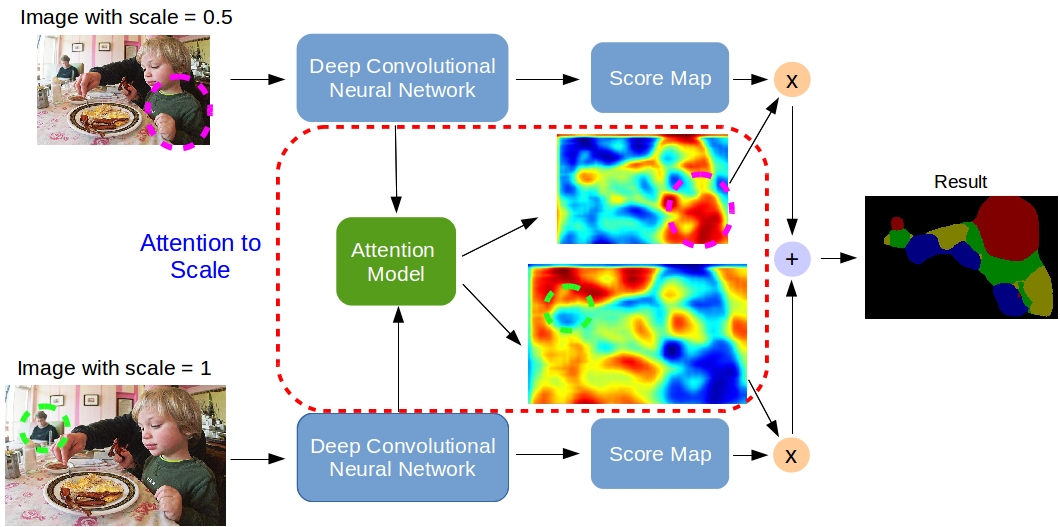
Figure 1. Model illustration. The attention model learns to put different weights on objects of different scales. For example, our model learns to put large weights on the small-scale person (green dashed circle) for features from scale = 1, and large weights on the large-scale child (magenta dashed circle) for features from scale = 0.5. We jointly train the network component and the attention model.
Related Work
Deep networks: Deep Convolutional Neural Networks (DCNNs). For the semantic image segmentation task, state- of-the-art methods are variants of the fully convolutional neural networks (FCNs).
Multi-scale features: skip-net, share-net.
Attention models for deep networks: apply attention in the 2D spatial and/or temporal dimension.
Attention to scale: To merge the predictions from multi- scale features, there are two common approaches: average- pooling [14, 15] or max-pooling [20, 44] over scales.
Model
Review of DeepLab
DeepLab reduces it to 8 by using the a trous (with holes) algorithm [39], and employs linear interpolation to upsample by a factor of 8.
LargeFOV, comes from the fact that the model adjusts the filter weights at the convolutional variant of fc6 (fc6 is the original first fully connected layer in VGG-16 net) with a trous algorithm so that its Field-Of-View is larger.
Attention model for scales
Based on share-net, suppose an input image is resized to several scales \(s \in \{1, \cdots, S\}\). Each scale is passed through the network and produces a score map, denoted as \(f_{i,c}^s\) where \(i\) ranges over all the spatial positions and \(c \in \{1, \cdots, C\}\) where \(C\) is the number of classes of interest. We denote \(g_{i,c}\) to be the weighted sum of score maps at \((i,c)\) for all scales, i.e.,
\[g_{i,c} = \sum_{s=1}^S w_i^s \cdot f_{i,c}^s\]
The weight \(w_i^s\) is computed by
\[w_i^s = \frac{\exp(h_i^s)}{\sum_{t=1}^S \exp(h_i^t)}\]
\(h_i^s\) is the score map produced by the attention model.
The attention model is parameterized by another FCN so that dense maps are produced.
The proposed attention model takes as input the convolutionalized fc7 features from VGG-16 [49], and it consists of two layers (the first layer has 512 filters with kernel size 3 × 3 and second layer has S filters with kernel size 1 × 1 where S is the number of scales employed).
We emphasize that the attention model computes a soft weight for each scale and position, and it allows the gradient of the loss function to be backpropagated through.
Extra supervision
In addition to the supervision introduced to the final output, we add extra supervision to the FCN for each scale [33].
The motivation behind this is that we would like to merge discriminative features (after pooling or attention model) for the final classifier output.
As pointed out by [33], discriminative classifiers trained with discriminative features demonstrate better performance for classification tasks.
We inject extra supervision to the final output of network for each scale so that the features to be merged are trained to be more discriminative.
Experimental Evaluations
we mainly experiment along three axes:
multi-scale inputs (from one scale to three scales with s ∈ {1, 0.75, 0.5}),
different methods (average-pooling, max-pooling, or attention model) to merge multi-scale features,
training with or without extra supervision.
PASCAL-Person-Part
We merge the annotations to be Head, Torso, Upper/Lower Arms and Upper/Lower Legs, resulting in six person part classes and one back- ground class.
We only use those images containing persons for training (1716 images) and validation (1817 images).
PASCAL VOC 2012
20 foreground object classes and one background class.
Subset of MS-COCO
The MS-COCO 2014 dataset [35] contains 80 foreground object classes and one background class.
The training set has about 80K images, and 40K images for validation.
We randomly select 10K images from the training set and 1,500 images from the validation set (same sizes as those we used for PASCAL VOC 2012).
Conclusion
Experiments on three datasets have shown that:
Using multi-scale inputs yields better performance than a single scale input.
Merging the multi-scale features with the proposed attention model not only improves the performance over average- or max-pooling baselines, but also allows us to diagnostically visualize the importance of features at different positions and scales.
Excellent performance can be obtained by adding extra supervision to the final output of networks for each scale.



