DCGAN
- Introduction
- Related Work
- Approach and Model Architecture
- Details Of Adversarial Training
- Empirical Validation Of Dcgans Capabilities
- Investigating and Visualizing the Internals of the Networks
(ICLR 2016) Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Paper: http://arxiv.org/abs/1511.06434
Code: https://github.com/Newmu/dcgan_code
Introduction
We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning.
Contributions:
- stable to train in most settings
- use the trained discriminators for image classification
- visualize the filters learnt by GANs
- generators have interesting vector arithmetic properties: easy manipulation
Related Work
Approach and Model Architecture
all convolutional net which replaces deterministic spatial pooling functions (such as maxpooling) with strided convolutions, allowing the network to learn its own spatial downsampling.
eliminating fully connected layers
global average pooling increased model stability but hurt convergence speed.
For the discriminator, the last convolution layer is flattened and then fed into a single sigmoid output.
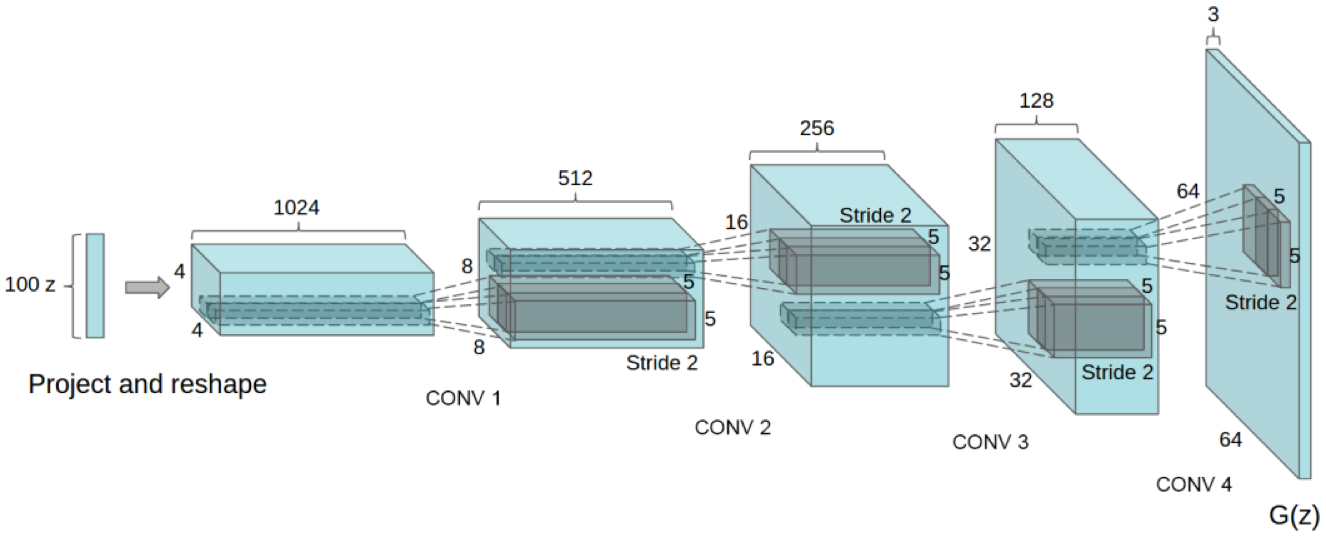
Figure 1: DCGAN generator used for LSUN scene modeling. A 100 dimensional uniform distribution Z is projected to a small spatial extent convolutional representation with many feature maps. A series of four fractionally-strided convolutions (in some recent papers, these are wrongly called deconvolutions) then convert this high level representation into a 64 × 64 pixel image. Notably, no fully connected or pooling layers are used.stabilizes learning by normalizing the input to each unit to have zero mean and unit variance.
using a bounded activation allowed the model to learn more quickly to saturate and cover the color space of the training distribution.
Architecture guidelines for stable Deep Convolutional GANs:
- Replace any pooling layers with strided convolutions (discriminator) and fractional-strided
convolutions (generator). - Use batchnorm in both the generator and the discriminator.
- Remove fully connected hidden layers for deeper architectures.
- Use ReLU activation in generator for all layers except for the output, which uses Tanh.
- Use LeakyReLU activation in the discriminator for all layers.
Details Of Adversarial Training
the suggested learning rate of 0.001 to be too high, using 0.0002 instead.
leaving the momentum term \(\beta\) at the suggested value of 0.9 resulted in training oscillation and instability while reducing it to 0.5 helped stabilize training.
LSUN
FACES
Imagenet-1k
Empirical Validation Of Dcgans Capabilities
Classifying CIFAR-10 Using GANs as a Feature Extractor
Classifying SVHN Digits Using GANs as a Feature Extractor
Investigating and Visualizing the Internals of the Networks
Walking in the Latent Space

Figure 4: Top rows: Interpolation between a series of 9 random points in Z show that the space learned has smooth transitions, with every image in the space plausibly looking like a bedroom. In the 6th row, you see a room without a window slowly transforming into a room with a giant window. In the 10th row, you see what appears to be a TV slowly being transformed into a window.
Visualizing the Discriminator Features
Manipulating the Generator Representation
Forgetting to Draw Certain Objects
the generator learns specific object representations for major scene components.Vector Arithmetic on Face Samples
simple arithmetic operations revealed rich linear structure in representation space.

Figure 7: Vector arithmetic for visual concepts. For each column, the Z vectors of samples are averaged. Arithmetic was then performed on the mean vectors creating a new vector Y . The enter sample on the right hand side is produce by feeding Y as input to the generator. To demonstrate the interpolation capabilities of the generator, uniform noise sampled with scale +-0.25 was added to Y to produce the 8 other samples. Applying arithmetic in the input space (bottom two examples) results in noisy overlap due to misalignment.



