pix2pix
Image-to-Image Translation Using Conditional Adversarial Networks
Paper: https://arxiv.org/pdf/1611.07004v1.pdf
Code: https://phillipi.github.io/pix2pix/
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems.
this work suggests we can achieve reasonable results without hand-engineering our loss functions either
Introduction
In analogy to automatic language translation, we define automatic image-to-image translation
as the problem of translating one possible representation of a scene into another, given sufficient training data (see Figure 1).
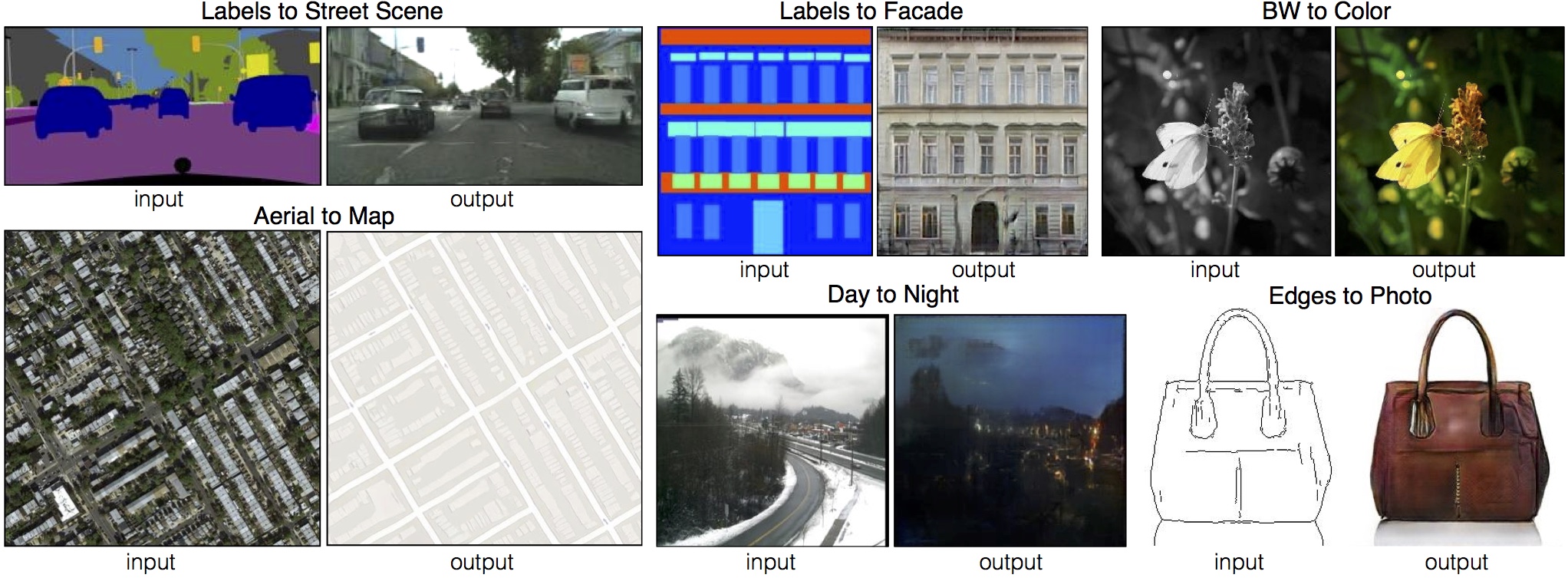
Figure 1: Many problems in image processing, graphics, and vision involve translating an input image into a corresponding output image. These problems are often treated with application-specific algorithms, even though the setting is always the same: map pixels to pixels. Conditional adversarial nets are a general-purpose solution that appears to work well on a wide variety of these problems. Here we show results of the method on several. In each case we use the same architecture and objective, and simply train on different data.
One reason language translation is difficult is because the mapping between languages is rarely one-to-one - any given concept is easier to express in one language than another.
Traditionally, each of these tasks has been tackled with separate, special-purpose machinery.
Our goal in this paper is to develop a common framework for all these problems.
although the learning process is automatic, a lot of manual effort still goes into designing effective losses.
Euclidean distance is minimized by averaging all plausible outputs, which causes blurring.
In this paper, we explore GANs in the conditional setting.
Contribution:
demonstrate that on a wide variety of problems, conditional GANs produce reasonable results.
present a simple framework sufficient to achieve good results, and to analyze the effects of several important architectural choices.
Related work
Structured losses for image modeling
Conditional GANs
Method
Objective
The objective of a conditional GAN can be expressed as
\[L_{cGAN} (G, D) = \mathbb{E}_{x, y \sim p_{data}(x, y)} [\log D(x, y)] + \mathbb{E}_{x \sim p_{data}(x), z \sim p_z(z)} [\log (1 - D(x, G(x, z))]\]
where G tries to minimize this objective against an adversarial D that tries to maximize it, i.e.
\[G^* = \arg \min_G \max_D L_{cGAN}(G, D)\]
Previous approaches to conditional GANs have found it beneficial to mix the GAN objective with a more traditional loss, such as L2 distance [29].
using L1 distance rather than L2 as L1 encourages less blurring
\[L_{L1}(G) = \mathbb{E}_{x, y \sim p_{data}(x, y), z \sim p_z(z)} [\lVert y - G(x, z) \rVert_1]\]
Our final objective is
\[G^* = \arg \min_G \max_D L_{cGAN}(G, D) + \lambda L_{L1}(G)\]
Instead, for our final models, we provide noise only in the form of dropout, applied on several layers of our generator at both training and test time.
Network architectures
Generator with skips
A defining feature of image-to-image translation problems is that they map a high resolution input grid to a high resolution output grid.
structure in the input is roughly aligned with structure in the output. We design the generator architecture around these considerations.
Encoder-decoder: the input is passed through a series of layers that progressively downsample, until a bottleneck layer, at which point the process is reversed (Figure 3).
For many image translation problems, there is a great deal of low-level information shared between the input and output, and it would be desirable to shuttle this information directly across the net.
we add skip connections, following the general shape of a "U-Net" (Figure 3).
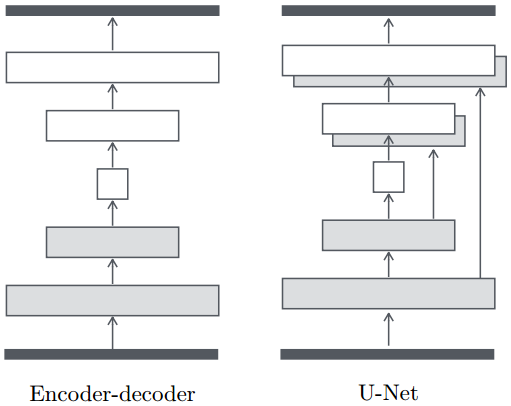
Figure 3: Two choices for the architecture of the generator. The "U-Net" [34] is an encoder-decoder with skip connections between mirrored layers in the encoder and decoder stacks.
Specifically, we add skip connections between each layer \(i\) and layer \(n − i\), where \(n\) is the total number of layers. Each skip connection simply concatenates all channels at layer \(i\) with those at layer \(n − i\).
Markovian discriminator (PatchGAN)
It is well known that the L2 loss - and L1, see Figure 4 - produces blurry results on image generation problems [22].
This motivates restricting the GAN discriminator to only model high-frequency structure, relying on an L1 term to force low-frequency correctness.
we design a discriminator architecture - which we term a PatchGAN - that only penalizes structure at the scale of patches.
This discriminator tries to classify if each \(N \times N\) patch in an image is real or fake.
This is advantageous because a smaller PatchGAN has fewer parameters, runs faster, and can be applied on arbitrarily large images.
Such a discriminator effectively models the image as a Markov random field, assuming independence between pixels separated by more than a patch diameter.
Optimization and inference
we alternate between one gradient descent step on D, then one step on G. We use minibatch SGD and apply the Adam solver [20].
we apply dropout at test time, and we apply batch normalization [18] using the statistics of the test batch, rather than aggregated statistics of the training batch.
Experiments
- Semantic labels <-> photo, trained on the Cityscapes dataset [4].
- Architectural labels -> photo, trained on the CMP Facades dataset [31].
- Map <-> aerial photo, trained on data scraped from Google Maps.
- BW -> color photos, trained on [35].
- Edges -> photo, trained on data from [49] and [44]; binary edges generated using the HED edge detector [42] plus postprocessing.
- Sketch -> photo: tests edges!photo models on human-drawn sketches from [10].
- Day -> night, trained on [21].
Data requirements and speed:
We note that decent results can often be obtained even on small datasets.
On datasets of this size, training can be very fast: for example, the results shown in Figure 12 took less than two hours of training on a single Pascal Titan X GPU. At test time, all models run in well under a second on this GPU.
Evaluation metrics
we employ two tactics:
run "real vs fake" perceptual studies on Amazon Mechanical Turk (AMT).
measure whether or not our synthesized cityscapes are realistic enough that off-the-shelf recognition system can recognize the objects in them.
AMT perceptual studies: For our AMT experiments, we followed the protocol from [46]
FCN-score: recent works [36, 39, 46] have tried using pre-trained semantic classifiers to measure the discriminability of the generated images as a pseudo-metric. The intuition is that if the generated images are realistic, classifiers trained on real images will be able to classify the synthesized image correctly as well.
Analysis of the objective function
L1 alone leads to reasonable but blurry results.
The cGAN alone (setting \(\lambda = 0\) in Eqn. 4) gives much sharper results, but results in some artifacts in facade synthesis.
the GAN-based objectives achieve higher scores, indicating that the synthesized images include more recognizable structure.
adding an L1 term also encourages that the output respect the input, since the L1 loss penalizes the distance between ground truth outputs, which match the input, and synthesized outputs, which may not.
Colorfulness: One might imagine cGANs have a similar effect on "sharpening" in the spectral dimension – i.e. making images more colorful.
Analysis of the generator architecture
A U-Net architecture allows low-level information to shortcut across the network.
when both U-Net and encoder-decoder are trained with an L1 loss, the U-Net again achieves the superior results (Figure 5).
From PixelGANs to PatchGans to ImageGANs
The PixelGAN has no effect on spatial sharpness, but does increase the colorfulness of the results.
Using a \(16 \times 16\) PatchGAN is sufficient to promote sharp outputs, but also leads to tiling artifacts.
to the full \(256 \times 256\) ImageGAN, does not appear to improve the visual quality of the results, and in fact gets a considerably lower FCN-score.
Perceptual validation
We validate the perceptual realism of our results on the tasks of map$aerial photograph and grayscale!color.
Semantic segmentation
To our knowledge, this is the first demonstration of GANs successfully generating “labels”, which are nearly discrete, rather than “images”, with their continuous-valued variation.
simply using L1 regression gets better scores than using a cGAN.
Conclusion
conditional adversarial networks are a promising approach for many image-to-image translation tasks, especially those involving highly structured graphical outputs.



