ICNet
- Introduction
- Related Work
- Speed Analysis
- Our Image Cascade Network
- Cascade Feature Fusion and Final Model
- Experimental Evaluation
- Conclusion
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
Paper: https://arxiv.org/abs/1704.08545
Code: https://github.com/hszhao/ICNet
基于PSPNet提出Image Cascade Network (ICNet),进行较高准确率的实时图片语义分割。
影响速度最重要的因素是图片分辨率,尝试了3种方法:对输入下采样,对特征下采样,模型压缩。但速度快了效果差很多。
输入低中高三种分辨率的图片,并提出Casecade Feature Fusion来融合三种feature map。训练时采用级联标签监督策略(缩小ground-truth来算loss并线性组合不同尺寸的loss)。
最后步进式地压缩模型:如果要保留1/2的kernel,则先保留3/4来fine-tune,然后再3/4,进行多次。
We propose an compressed-PSPNet-based image cascade network (ICNet) that incorporates multi-resolution branches.
Introduction

Figure 1. Inference speed and mIoU performance on Cityscapes [5] test set. Methods involved are ResNet38 [30], PSPNet [33], DUC [29], RefineNet [14], LRR [6], FRRN [22], DeepLabv2 [3], Dilation10 [32], DPN [18], FCN-8s [19], DeepLab [2], CRF-RNN [34], SQ [28], ENet [21], SegNet [1], and our ICNet.
Our experiments show that high-accuracy methods of PSPNet [33] and ResNet38 [30] take more than 1 second to predict a 1024 × 2048 high-resolution image on one Nvidia TitanX GPU card during testing. These methods fall into the area illustrated in Figure 1 with high accuracy and low speed.
Recent fast semantic segmentation methods of SegNet [1], ENet [21], and SQ [28], contrarily, take quite different positions in the plot of Figure 1. The speed is much accelerated; but accuracy notably drops, where the final mIoUs are lower than 60%. These methods locate near the right bottom corner in Figure 1.
The idea is to let low-resolution image go through the full semantic perception network first for a coarse prediction map. Then the proposed cascade fusion unit introduces middle- and high-resolution image feature and improves the coarse semantic map gradually.
contributions:
We develop an image cascade network (ICNet), which utilizes semantic information in low resolution along
with details from high-resolution images efficiently.The proposed ICNet achieves 5x+ speedup of inference, and reduces memory consumption by 5+ times.
Our proposed fast semantic segmentation system can run at resolution 1024×2048 in speed of 30.3 fps while accomplishing high-quality results.
Related Work
High Quality Semantic Segmentation
Fast Semantic Segmentation
SegNet [1] abandons layers to reduce layer parameters and ENet [21] is a lightweight network.
Video Segmentation Architectures
Clockwork [27] reused feature maps given stable video input. Deep feature flow [35] was based on a small-scale optical flow network to propagate features from key frames to others.
Speed Analysis
Time Budget
We first study influence of image resolution in semantic segmentation using PSPNet.
In additional to image resolution, width of a network or the number of kernels also effect the inference time.
Intuitive Speedup
Downsampling Input
A simple approach is to use the small-resolution image as input.
although the inference time is reduced by a large margin, the prediction map is very coarse, missing many small but important details compared to the higher resolution prediction.
Downsampling Feature
scale down the feature map by a large ratio in the inference process.
| Downsample Size | 8 | 16 | 32 |
|---|---|---|---|
| mIoU (%) | 71.7 | 70.2 | 67.1 |
| Time (ms) | 446 | 177 | 131 |
Table 1. Total time spent on PSPNet50 when choosing downsampling factors 8, 16 and 32.
A smaller feature map can yield faster inference at the cost of sacrificing prediction accuracy. The lost information is similarly details contained in low-level layers.
Model Compression
trim kernels in each layer
For each filter, we first calculate the L1 sum of its kernel weights. Then we sort these L1 sums in a descending order for keeping only the most significant ones.
| Kernel Keeping Rates | 1 | 0.5 | 0.25 |
|---|---|---|---|
| mIoU (%) | 71.7 | 67.9 | 59.4 |
| Time (ms) | 446 | 170 | 72 |
Table 2. Kernel keeping rates in model compression along with related mIoUs and inference time.
the inference time is still too long. Meanwhile the corresponding mIoU is intolerably low
Our Image Cascade Network
Main structures and Branches
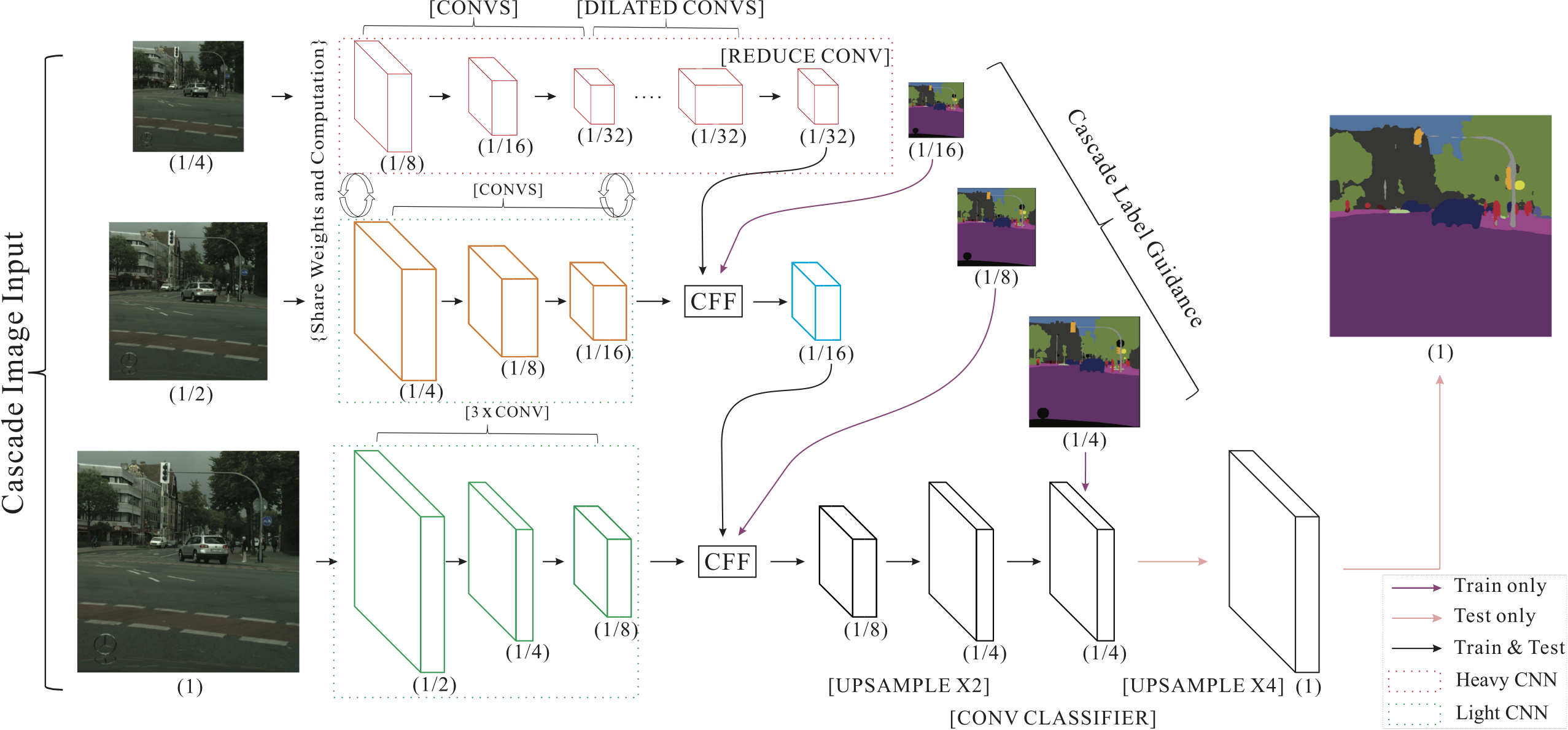
Low Resolution
For the lowest resolution input, it goes through the top branch, which is an FCN-based PSPNet architecture. Since the input size is only 1/4 of the original one, convolution layers correspondingly downsize the feature maps by a ratio of 1/8 and yield 1/32 of the original spatial size.
Median Resolution
For the 1/2 size middle-resolution image, the output feature maps are of size 1/16 of the original ones.
To fusion the 1/16 size feature map with the 1/32 size feature map in the top branch, we propose a cascade feature fusion (CFF) unit that will be discussed later in this paper.
the convolutional parameters can be shared between the 1/4 and 1/2 resolution inputs, thus saving computational and reducing parameter number.
High Resolution
A 1/8 size feature map is resulted.
we use the CFF unit to incorporate the output of previous CFF unit and current feature map in full resolution in branch three.
Cascade Label Guidance
It uses 1/16, 1/8, and 1/4 of ground truth labels to guide the learning stage of low, median and high resolution input.
Branch Analysis
branch one: even with more than 50 layers, the inference operation and memory consumption are not large as 18ms and 0.6GB.
There are 17 convolutional layers in branch two and only 3 in branch three.
only 6ms more is spent to construct the fusion feature map using two branches.
the inference time in branch three is just 9ms.
Difference from Other Cascade Structures
these methods focus on fusing features from different layers from a single-scale input or multi-scale ones.
They all face the same problem of expensive computation given high-resolution input.
our ICNet uses the low-resolution input to go through the main semantic segmentation branch and adopts the high-resolution information to help refinement.
Cascade Feature Fusion and Final Model

Figure 6. Cascade feature fusion unit. Given input two feature maps \(F_1\) and \(F_2\) where the spatial resolution of the latter is twice of the former one, the fused feature map \(F'_2\) is of the same spatial size as \(F_2\).
The input to this unit contains three components: the two feature maps F1 and F2 of resolution \(H1 \times W1 \times C1\) and \(H2 \times W2 \times C2\) and a ground truth label in resolution \(H2 \times W2 \times 1\).
Upsampling is applied to make F1 the same size as F2. Then a dilated convolution layer with kernel size \(3 \times 3\) and dilation 1 is applied to refine upsampled features.
for feature F2, a projection convolutional layer with kernel size \(1 \times 1\) is utilized to project it with the same size as the output of feature F1.
Then two batch normalization layers are used to normalize these two features.
To enhance learning of F1, we use an auxiliary label guidance to the upsampled F1. The auxiliary loss weight is set to 0.4 as in [33].
The Loss Function
To train ICNet, we append softmax cross entropy loss in each branch denoted as \(L_1\), \(L_2\) and \(L_3\) with corresponding weights \(\lambda_1\), \(\lambda_2\), and \(\lambda_3\).
\(L = \lambda_1 L_1 + \lambda_2 L_2 + \lambda_3 L_3\)
All the losses we adopted are the cross-entropy loss on the corresponding downsampled score maps.
Final Model Compression
We compress our model in a progressive way. Taking compression rate 1/2 as an example, instead of removing a half of kernels directly, we first choose to keep 3/4 of the kernels and initialize this compressed model for following fine tuning. After it is done, we remove more kernels and repeat this process until the goal of compression is achieved.
For each filter, we calculate the L1 sum of its kernel weights.
Then we sort these sums in a descending order for ranking.
Finally, we remove those least important kernels which have smaller weights.
Experimental Evaluation
We conduct experiments based on learning platform Caffe [12].
Our testing uses only one card.
Our network structure is modified from PSPNet.
We changed the concatenation operations in the pyramid pooling module to summation, thus reducing feature length from 4096 to 2048.
We changed the kernel size in the convolution layer after pyramid pooling from original \(3 \times 3\) to \(1 \times 1\). It does not much affect final accuracy but saves computation a lot.
To train the hyper-parameters, the mini-batch size is set to 16.
Dataset and Evaluation Metrics
Cityscapes
high-resolution images up to \(1024 \times 2048\)
training/validation/testing: 2975/500/1525
contains 30 common class labels, 19 of them are used in training and testing
For evaluation, both mean of class-wise intersection over union (mIoU) and network forward time are used.
Model Compression
| Items | Baseline | ICNet |
|---|---|---|
| mIoU (%) | 67.9 | 67.7 |
| Time (ms) | 170 | 33 |
| Frame (fps) | 5.9 | 30.3 |
| Speedup | 1x | 5.2x |
| Memory (G) | 9.2 | 1.6 |
| Memory Save | 1x | 5.8x |
Table 3. Performance of baseline and ICNet on validation set of Citysapes. The baseline method is the structure-optimized PSPNet50 with compress operation by half.
They indicate that only model compression has almost no chance to achieve realtime
performance under the condition of keeping decent segmentation quality.
In what follows, we take the model-compressed PSPNet50, which is reasonably accelerated, as our baseline system for comparison.
Ablation Study for Image Cascade Framework
| Items | Baseline | sub4 | sub24 | sub124 |
|---|---|---|---|---|
| mIoU (%) | 67.9 | 59.6 | 66.5 | 67.7 |
| Time (ms) | 170 | 18 | 25 | 33 |
| Frame (fps) | 5.9 | 55.6 | 40 | 30.3 |
| Speedup | 1x | 9.4x | 6.8x | 5.2x |
| Memory (GB) | 9.2 | 0.6 | 1.1 | 1.6 |
| Memory Save | 1x | 15.3x | 8.4x | 5.8x |
Table 4. Our ICNet performance on the validation set of Cityscapes with different settings.
The setting ‘sub4’ only uses the top branch with the low-resolution input. ‘sub24’ and ‘sub124’ respectively contain top two and all three branches.
Visual Comparison
Quantitative Analysis
Final Results and Comparison
Conclusion
We have proposed a realtime semantic segmentation system ICNet. It incorporates effective strategies to simplify network structures without significantly reducing performance.



