VAEGAN
(ICML 2016) Autoencoding beyond pixels using a learned similarity metric
Paper: https://arxiv.org/abs/1512.09300
Code: https://github.com/andersbll/autoencoding_beyond_pixels
We present an autoencoder that leverages learned representations to better measure similarities in data space.
By combining a variational autoencoder (VAE) with a generative adversarial network (GAN) we can use learned feature representations in the GAN discriminator as basis for the VAE reconstruction objective.
we replace element-wise errors with feature-wise errors to better capture the data distribution while offering invariance towards e.g. translation.
we show that the method learns an embedding in which high-level abstract visual features (e.g. wearing glasses) can be modified using simple arithmetic.
Introduction
we show that currently used similarity metrics impose a hurdle for learning good generative models and that we can improve a generative model by employing a learned similarity measure.
Element-wise metrics are simple but not very suitable for image data, as they do not model the properties of human visual perception.
We collapse the VAE decoder and the GAN generator into one by letting them share parameters and training them jointly.
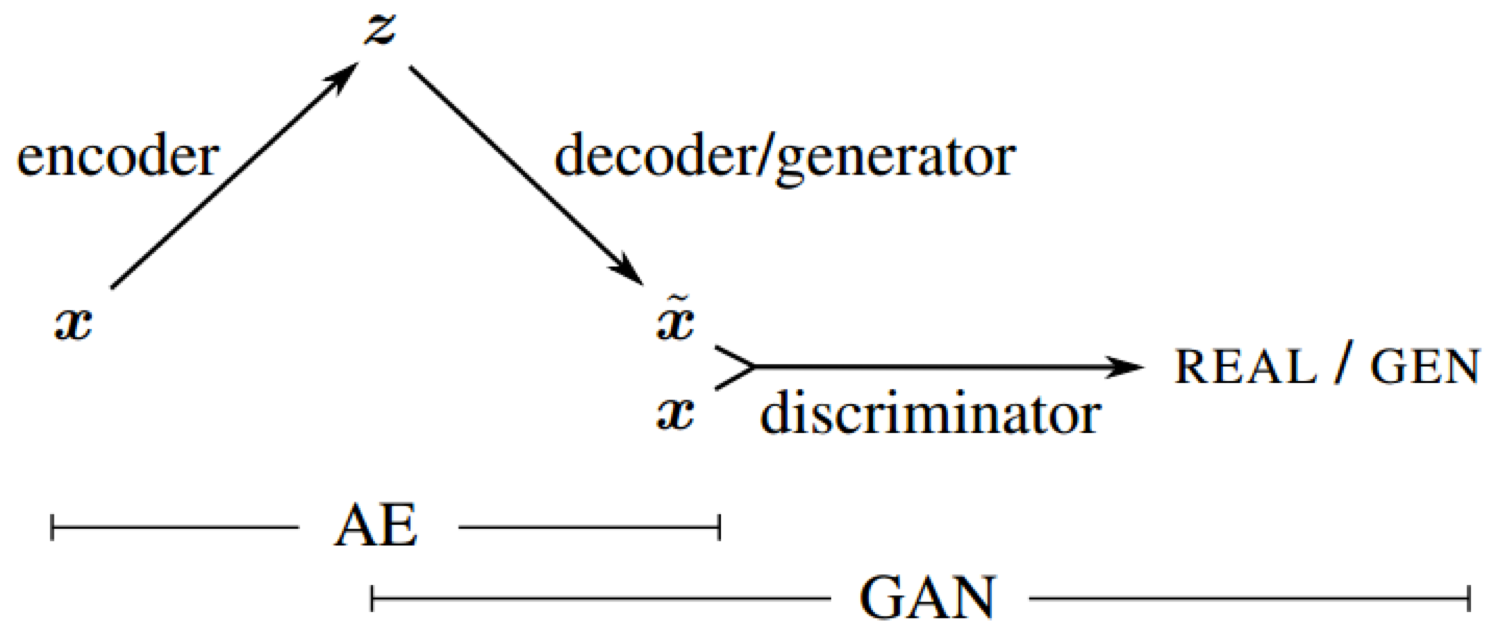
Figure 1. Overview of our network. We combine a VAE with a GAN by collapsing the decoder and the generator into one.
Contributions
We combine VAEs and GANs into an unsupervised generative model that simultaneously learns to encode, generate and compare dataset samples.
We show that generative models trained with learned similarity measures produce better image samples than models trained with element-wise error measures.
We demonstrate that unsupervised training results in a latent image representation with disentangled factors of variation (Bengio et al., 2013).
Autoencoding with learned similarity
Variational autoencoder
Generative adversarial network
Beyond element-wise reconstruction error with VAE/GAN
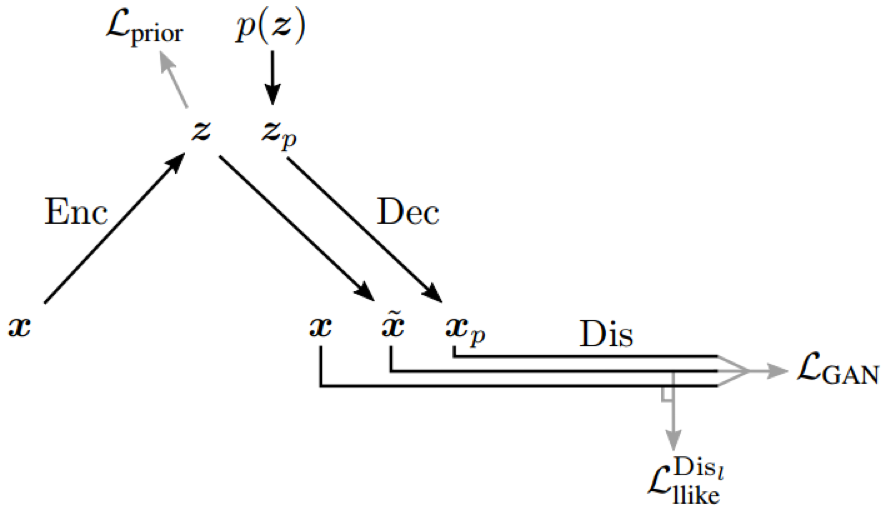
Figure 2. Flow through the combined VAE/GAN model during training. Gray lines represent terms in the training objective.



