Towards Real World Human Parsing: Multiple-Human Parsing in the Wild
Paper: https://arxiv.org/pdf/1705.07206.pdf
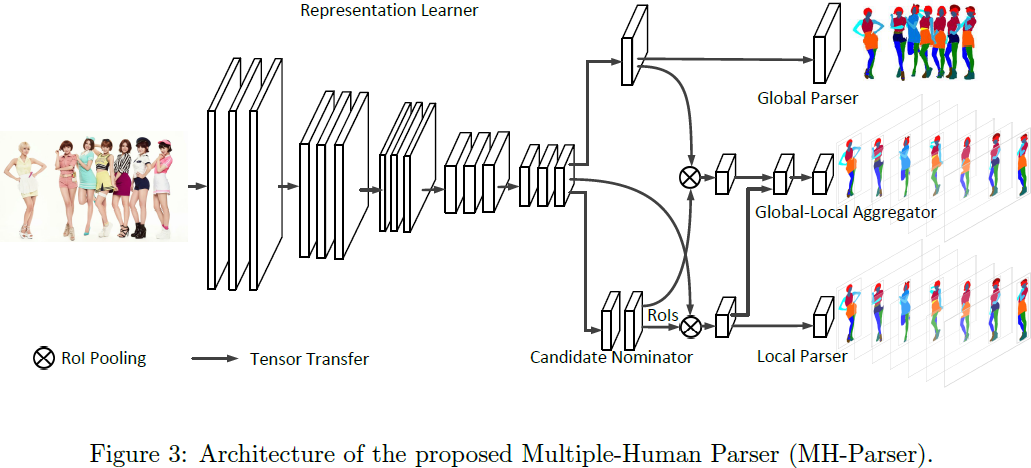
Towards Real World Human Parsing: Multiple-Human Parsing in the Wild
Paper: https://arxiv.org/pdf/1705.07206.pdf
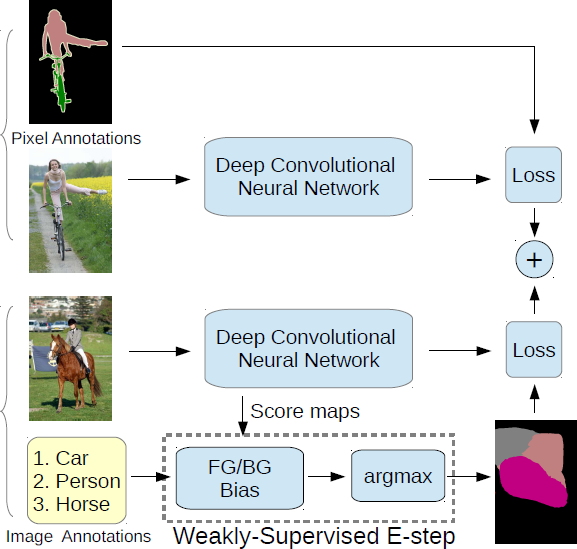
(ICCV 2015) Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
Paper: http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Papandreou_Weakly-_and_Semi-Supervised_ICCV_2015_paper.pdf
Project Page: http://liangchiehchen.com/projects/DeepLab_Models.html
Code: https://bitbucket.org/deeplab/deeplab-public/
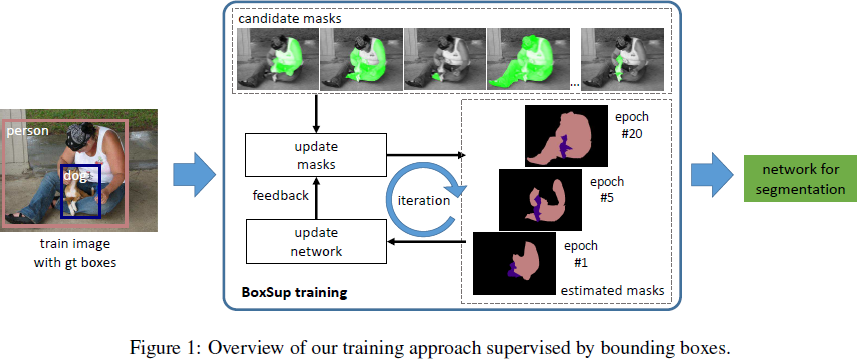
(ICCV 2015) BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation
Paper: http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Dai_BoxSup_Exploiting_Bounding_ICCV_2015_paper.pdf
(ICCV 2015) Human Parsing with Contextualized Convolutional Neural Network
(T-PAMI 2016) Human Parsing with Contextualized Convolutional Neural Network
Paper: http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Liang_Human_Parsing_With_ICCV_2015_paper.pdf
http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7423822&queryText=human%20parsing%20with%20contextualized&newsearch=true
Project: http://hcp.sysu.edu.cn/deep-human-parsing/

(CVPR 2017) Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing
Paper: http://www.linliang.net/files/CVPR17_LIP.pdf
Project: http://hcp.sysu.edu.cn/lip/index.php
Code: https://github.com/Engineering-Course/LIP_SSL

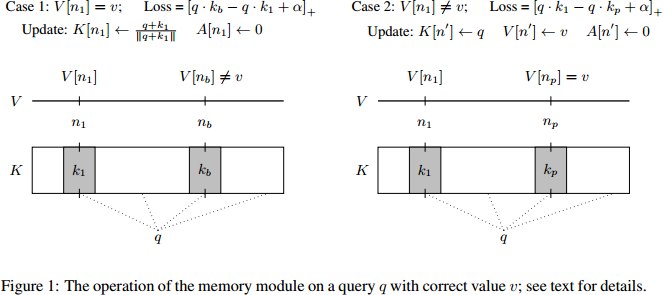
(ICLR 2017) Learning to Remember Rare Events
Paper: https://openreview.net/pdf?id=SJTQLdqlg
Code: https://github.com/tensorflow/models/tree/master/learning_to_remember_rare_events
(ICLR 2017) Hypernetworks
Paper: https://openreview.net/pdf?id=rkpACe1lx
Code: https://github.com/hardmaru/supercell
Blog: http://blog.otoro.net/2016/09/28/hyper-networks/

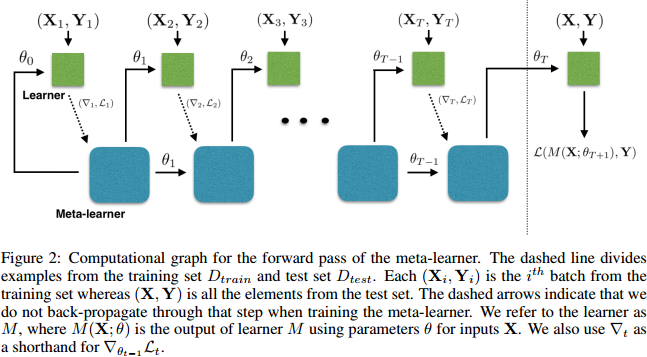
(ICLR 2017) Optimization As a Model For Few-Shot Learning
Paper: https://openreview.net/pdf?id=rJY0-Kcll
Code: https://github.com/twitter/meta-learning-lstm
(NIPS 2016 Workshop) Semantic Segmentation using Adversarial Networks
Paper: https://arxiv.org/abs/1611.08408
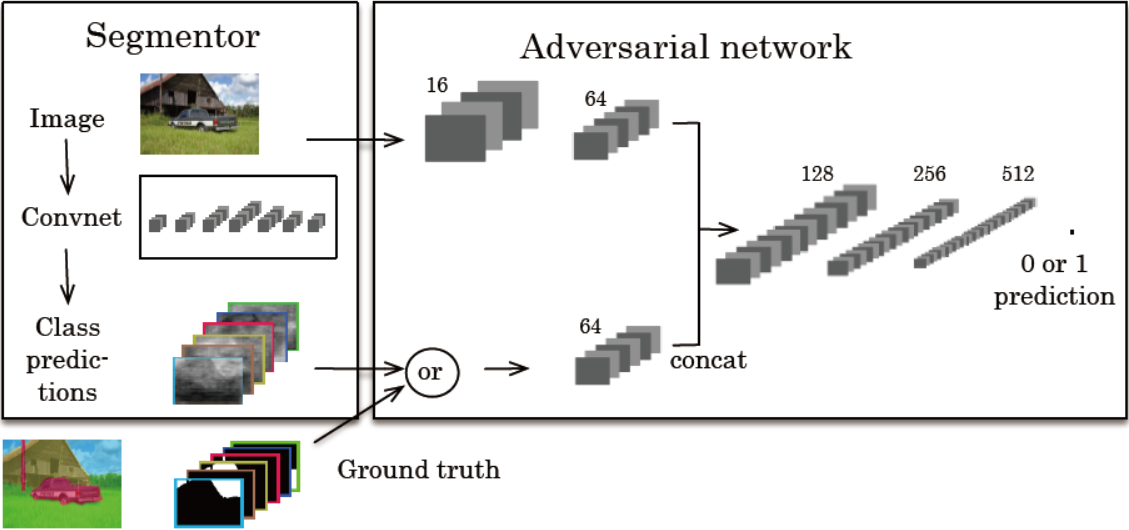
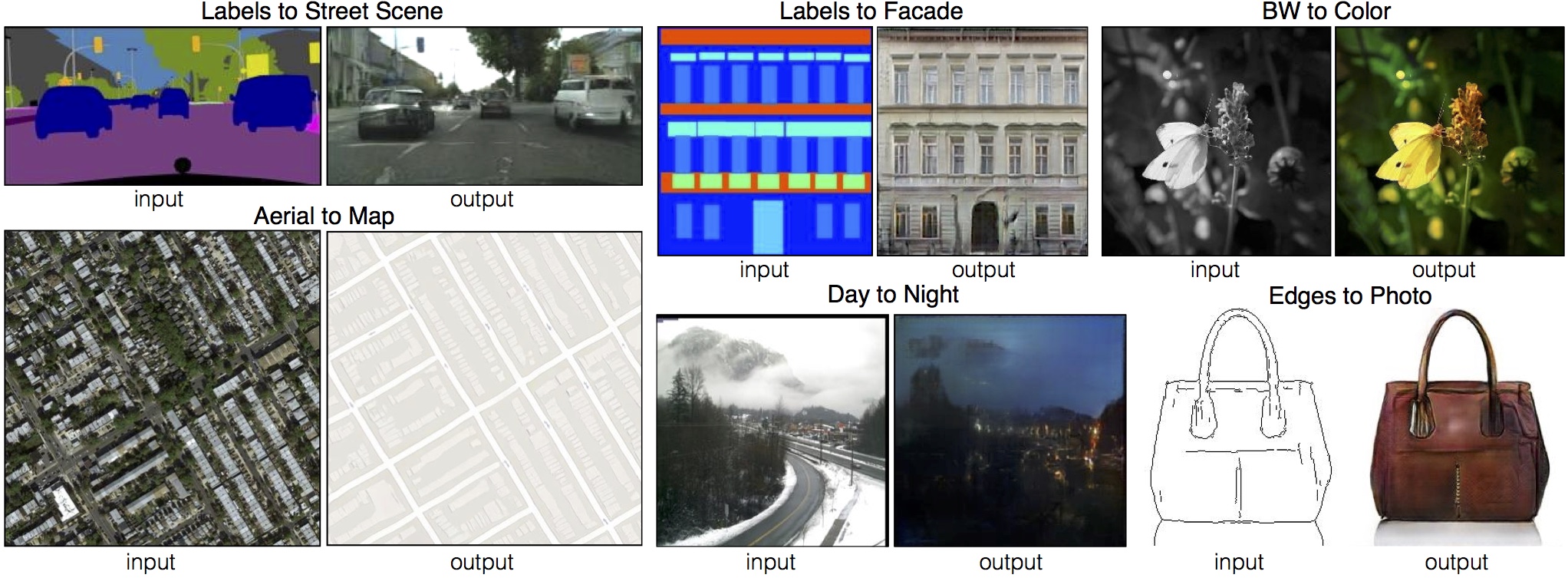
Image-to-Image Translation Using Conditional Adversarial Networks
Paper: https://arxiv.org/pdf/1611.07004v1.pdf
Code: https://phillipi.github.io/pix2pix/